Discover Financial Spreading 2.0 With StackFin
Take intelligent decision-making to the next level through Pixel-Based Machine Learning Technology.

About Financial Spreading 2.0
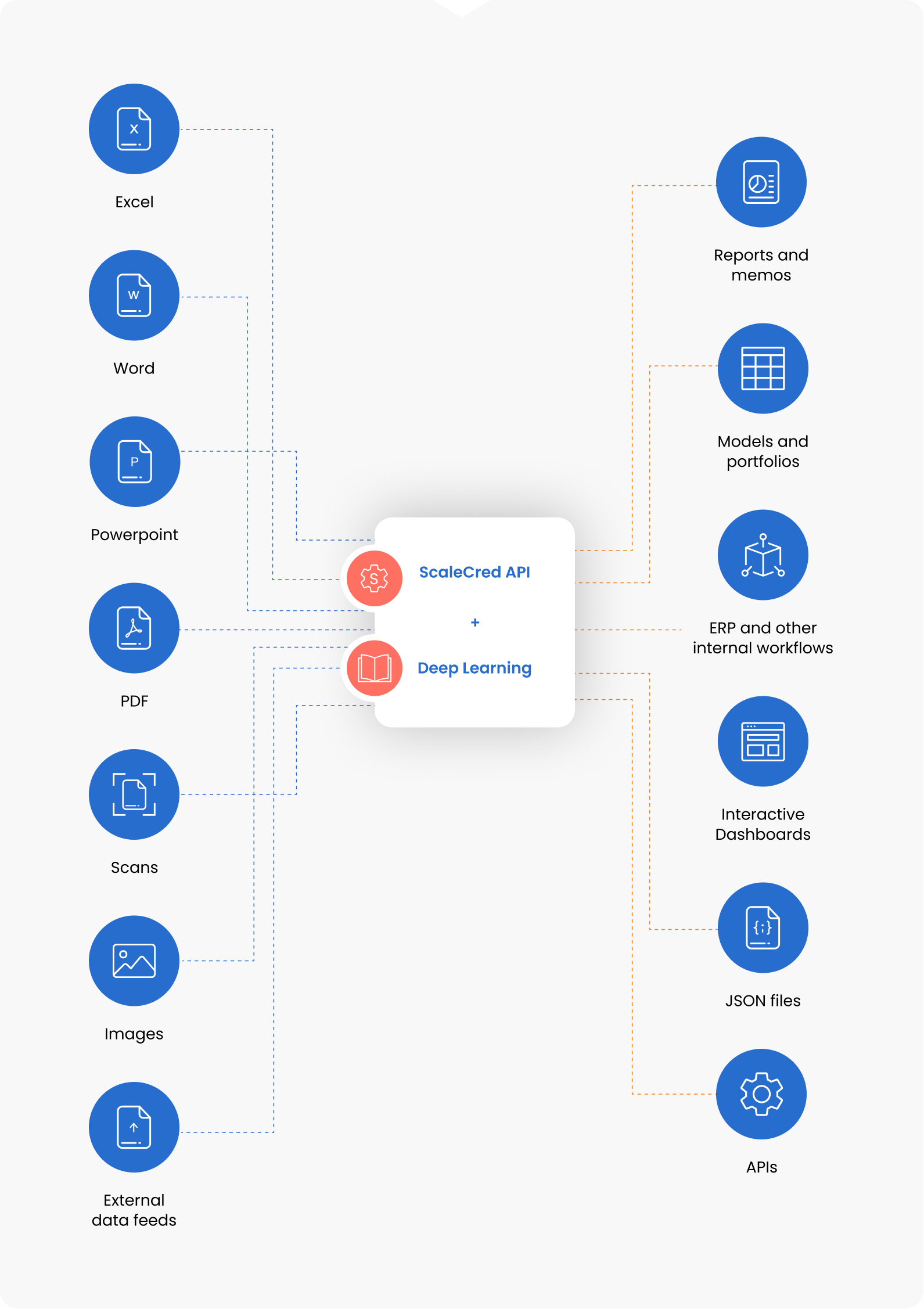
It’s a financial spreading platform based on proprietary Pixel-Based Machine Learning Technology (PBMLT). It eliminates all manual and repetitive processes so that your time is spent on the most critical activity: analysis.
The power of cognitive technologies and deep learning allows data to be extracted at the most granular level from any document format in the fastest time. Our machine learning algorithms have been trained to ensure that the final output conforms to your proprietary methodology. Inconsistencies are identified and rectified by auto-check quality processes.

Financial Spreading 2.0 at a Glance
Powered by Cognitive Technologies and Deep Learning

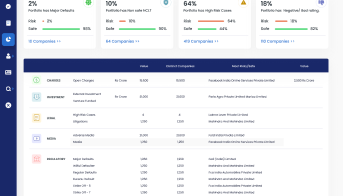
Comprehensive Existing Database
Comprehensive existing database of financial spreads comprising thousands of public and private companies.

Automated Data Extraction
Data is extracted via machine learning algorithms from any type of document, including JPEG, PDF, Word, PowerPoint and scanned documents.

Customized Final Output
Data from the original layout is reconstructed, synthesized and mapped to clients’ output formats and in sync with their methodology.

Seamless Integration
Secure and seamless integration of clients’ proprietary (private) data with publicly-available financial data through APIs.

Higher Data Accuracy
10x increase in data accuracy using a combination of pixel-based character recognition, page recognition and machine learning technology.

Significant Efficiency Gains
Significant reduction in manual effort and turnaround time results in up to 90% efficiency gains.
Financial Spreading Redefined...
Going beyond optical character recognition (OCR)
-

Different file formats or handwritten
-

Tabular format
-

Different font styles or font size
-

Scanned copies with high “noise” levels
Pixel-Based Machine Learning Technology overcomes these limitations through pixel-based character recognition that has the ability to extract data from any document format.
...To Give You Speed, Accuracy and Standardization
Comprehensive features deliver trustworthy financial data

Page recognition from any documnet

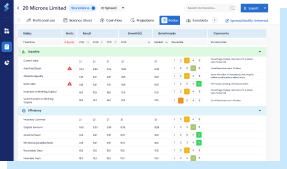
Result validation

Pixel-by-pixel character recognition
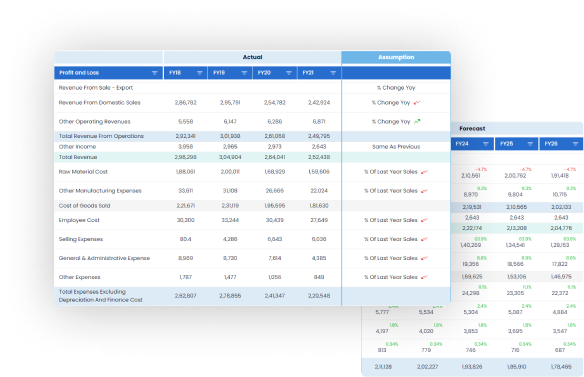
Looking Insights

Accurate Results
Delivered With Speed








=
1 minute to 4 hours
User-Friendly Features Offer Flexibility and Convenience
Any Time, Anywhere Access
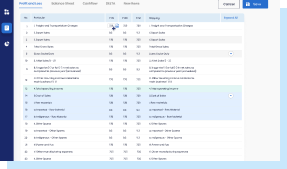
Log in to the StackFin database from anywhere and at any time. Use your login credentials to access an existing database of nearly 40,000 spreads.
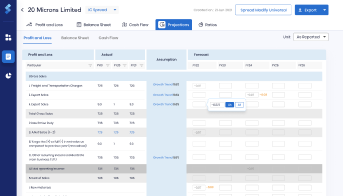
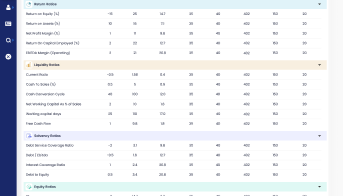
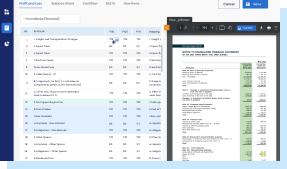
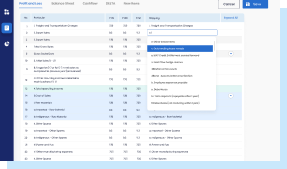
Easy Report Upload
Add new reports at the click of a few buttons. Reports of different formats - such as annual report, investor presentation, rating report - can be added.
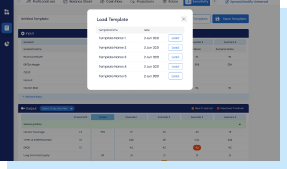
Instant Download
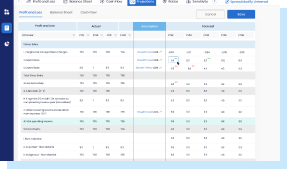
Export the final output into a standard or customized template and download it instantly once the entire process is complete.
Eliminate Manual Processes for Significant Efficiency Gains
| Manual | ScaleCred | |
|---|---|---|
|
Document Sourcing
|
|
|
|
Document Processing
|
|
|
|
Data Validation
|
|
|
|
Turnaround Time
|
|
|
Accelerate Automation and Streamline Processes